Sitemap Topology
To include your site in its search results, Google uses a googlebot to crawl your site. Google knows what pages are new in your site using the sitemap you provide. When Google requests the sitemap, the SiteMap pipeline in your application serves the sitemap to Google, using the SendGoogleSiteMap pipelet.
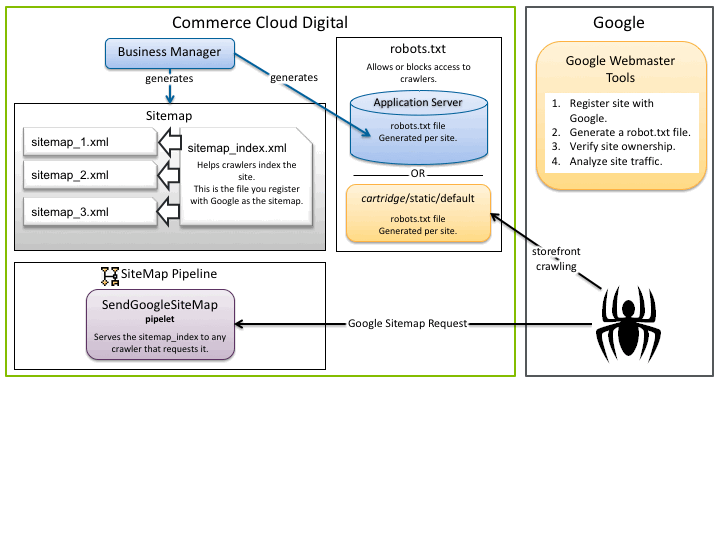
The sitemap is composed of one index file
(sitemap_index.xml), and one or more actual sitemap
files (sitemap_0.xml, sitemap_1.xml, ...).
The index file is the file that you register with the search engine, which contains the locations of all sitemap files. Its only purpose is to point to the actual sitemaps. The actual number of sitemap files are determined by the configurable URLs per sitemap file (for example, 50,000) or by a maximum size of 10 MB per sitemap file, whichever condition is reached first.
The googlebot indexes your site, which tells Google exactly what information is included on each page. The googlebot uses the robots.txt file to determine what parts of the site to index. Googlebots don't index parts of your site disallowed by the robots.txt file, even if the URLs are included in your sitemap.
You can generate a robots.txt file using the Google Webmaster tools and use it across several sites. You can also generate the robots.txt file in Business Manager and serve it to crawlers per site.
Related Links